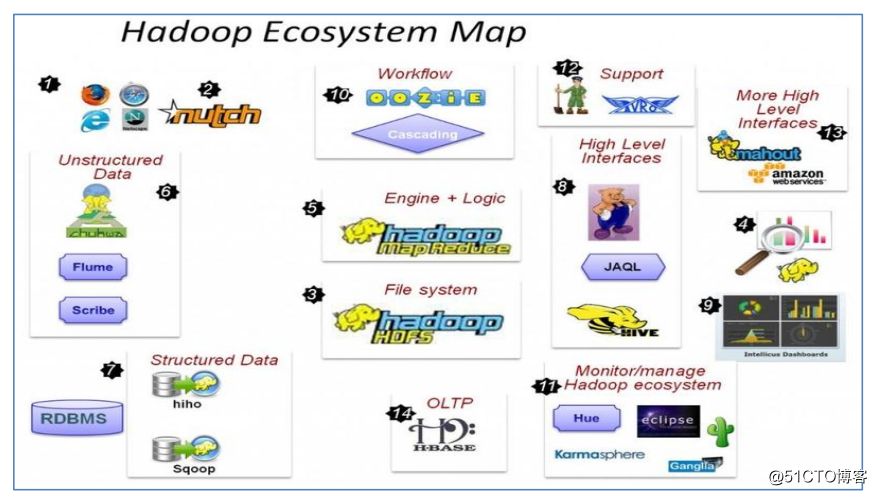
hadoop生态的大体介绍
本文共 613 字,大约阅读时间需要 2 分钟。
数据的处理流程:
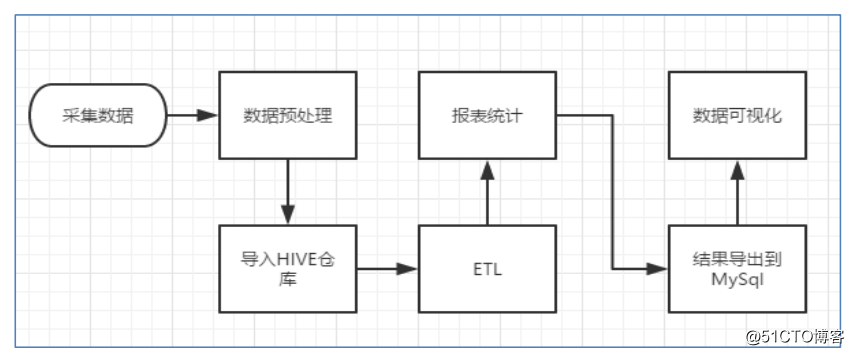 A、数据采集:定制开发采集程序,或使用开源框架 Flume 或者 LogStashB、数据预处理:定制开发 MapReduce 程序运行于 Hadoop 集群,或者专门数据收集工具也能进行数据预处理C、数据仓库技术:基于 Hadoop 之上的 HiveD、数据导出:基于 Hadoop 的 Sqoop 数据导入导出工具E、数据可视化:定制开发 web 程序或使用 Kettle 等产品F、数据统计分析:Hadoop 中的 MapReduce 或者基于 Hadoop 的 Hive,或者 Spark,FlinkG、整个过程的流程调度:Hadoop 生态圈中的 Oozie/Azkaban 工具或其他类似开源产品
A、数据采集:定制开发采集程序,或使用开源框架 Flume 或者 LogStashB、数据预处理:定制开发 MapReduce 程序运行于 Hadoop 集群,或者专门数据收集工具也能进行数据预处理C、数据仓库技术:基于 Hadoop 之上的 HiveD、数据导出:基于 Hadoop 的 Sqoop 数据导入导出工具E、数据可视化:定制开发 web 程序或使用 Kettle 等产品F、数据统计分析:Hadoop 中的 MapReduce 或者基于 Hadoop 的 Hive,或者 Spark,FlinkG、整个过程的流程调度:Hadoop 生态圈中的 Oozie/Azkaban 工具或其他类似开源产品 转载于:https://blog.51cto.com/14048416/2341495
你可能感兴趣的文章
Cent OS 环境下 samba服务器的搭建
查看>>
vCloud Director 1.5.1 Install Procedure
查看>>
hive 中的多列进行group by查询方法
查看>>
Cisco统一通信---视频部分
查看>>
nginx编译及参数详解
查看>>
VMware下PM魔术分区使用教程
查看>>
nslookup错误
查看>>
我的友情链接
查看>>
Supported plattforms
查看>>
做自己喜欢的事情
查看>>
CRM安装(二)
查看>>
Eclipse工具进行Spring开发时,Spring配置文件智能提示需要安装STS插件
查看>>
NSURLCache内存缓存
查看>>
jquery click嵌套 事件重复注册 多次执行的问题
查看>>
Dev GridControl导出
查看>>
开始翻译Windows Phone 8 Development for Absolute Beginners教程
查看>>
Python tablib模块
查看>>
站立会议02
查看>>
Windows和Linux如何使用Java代码实现关闭进程
查看>>
0428继承性 const static
查看>>